
As part of the 2017 Global Legislative Openness Week K-Monitor did some experimenting with parliamentary data. Background: K-Monitor started to scrape data from the Hungarian Parliament's website to make it processable for researchers and easily searchable for citizens and journalists. The following is an English summary of the preliminary results, more to follow in spring.

(Click on the picture to proceed to the project page - HU)
Our first chart displays the lexical diversity of the texts analysed. You get this by dividing the number of words of a text with the unique words. So, in the sentence “to be, or not to be” you have 6 words and 4 unique words, thus the lexical diversity of the sentence is 6/4=1.5. The higher the amount, the more repetition is in a text. Click on the chart for the interactive version.
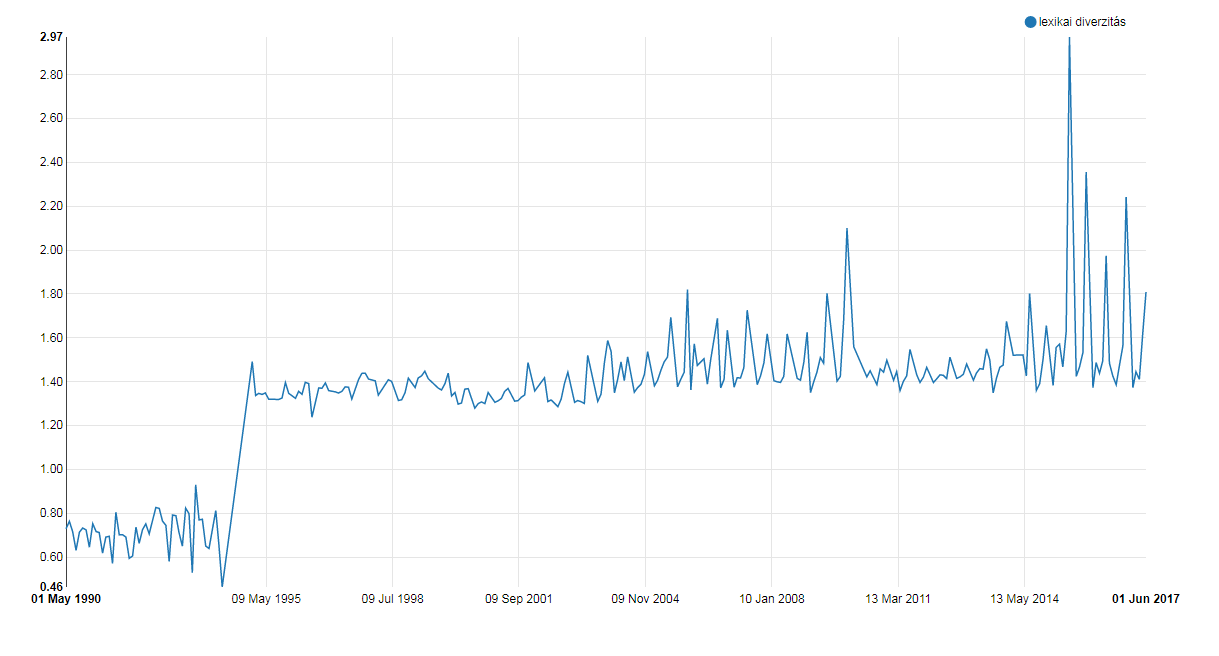 Above: Lexical diversity of speeches in the Hungarian Parliament (below 1 results due to poor data quality of texts from 1990-1994)
Above: Lexical diversity of speeches in the Hungarian Parliament (below 1 results due to poor data quality of texts from 1990-1994)
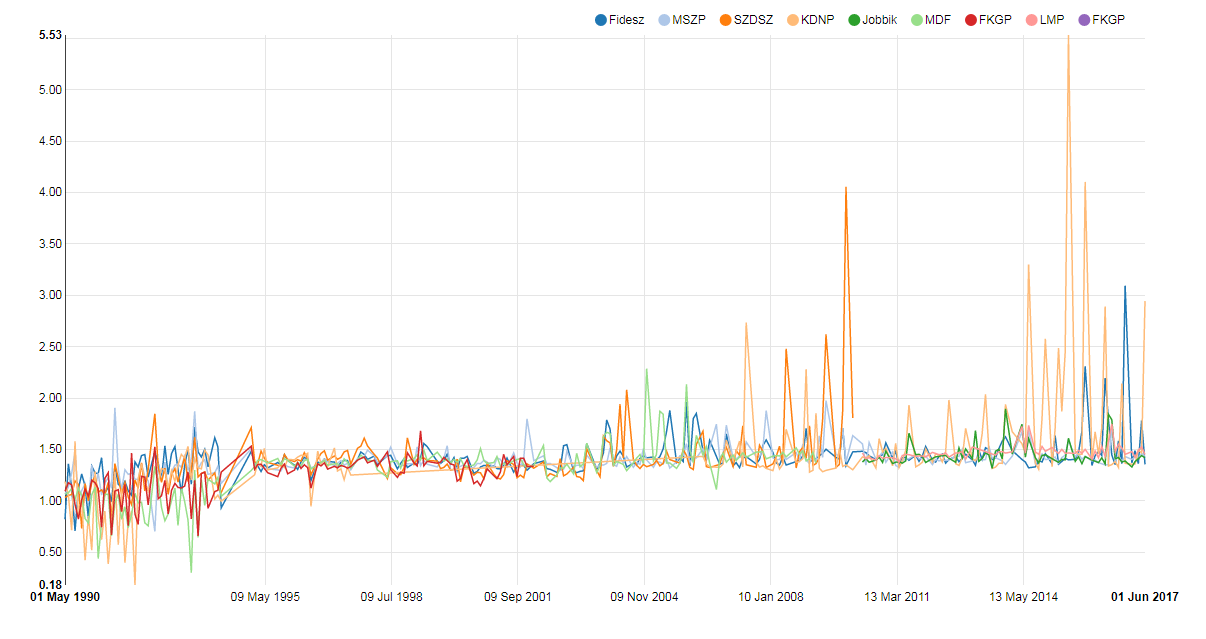 Above: Lexical diversity of speeches in the Hungarian Parliament by parties (below 1 results due to poor data quality of texts from 1990-1994)
Above: Lexical diversity of speeches in the Hungarian Parliament by parties (below 1 results due to poor data quality of texts from 1990-1994)
If you take a look at the party breakdown of lexical diversity, you will see that since 2010 there are surges in the values. Our hypothesis is that the surges were caused by recurring and ongoing themes in Parliamentary debates, such as the quota-referendum and migration crisis. To identify any correlation, we need further analysis of the speeches made in the National Assembly during the time period of the surges on the table. However, we must point out that in spoken language we have a tendency to repeat in order to emphasize our point, thus the lexical diversity of a spontaneous speech could also be around 10. Furthermore, over times Parliamentary speeches evolved into being more easily quotable for the media as well.
Chart 3 focuses on the themes spoken of in Parliament. Using the latent Dirichlet allocation with machine learning we identified 19 main groups. The labelling of the topics is subjective, and as a result of the uniqueness of the methodology they should not be considered “clean”. We created these based on the theme best describing the word-cloud collected. These could (and probably will) further change as the project goes on. Hovering over the blobs shows what percentage that topic took up in that respective year.
Table 4 shows the spread of topics between 1990-2017. Hovering over the columns shows the words included in that topic. It is interesting to see, that educational, family and social policies are the least emphasized themes in Parliament. We believe that ‘media’ surged as a result of the media-law package of the Orbán government, whereas topics such as taxation, pensions and social security are frequently talked about. The methodology needs some adjustment in this segment as well.
As said, this post is just an insight into a research we're doing over the next months. Results can change as scrapers will be improved, and amound of data will grow). Beside getting a more deeper understanding of the Hungarian Parliement's work, we also aim to make data easily searchable through a simple online platform. We further plan to profile MPs and parties based on the lexicality of their speeches and their favoured topics, with the ability to compare these. If you'd like support this project, we appriciate your contribution through the link below.
|
Support K-Monitor and the fight against corruption in Hungary ▶︎ Donate via bank transfer or PayPal: k-monitor.hu/support
|
Címkék: english
Szólj hozzá!
Ajánlott bejegyzések:





A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.